#!/bin/bash
host=202.100.222.2 #FTP主机
UserName=test #FTP用户名
Passwd=test #FTP密码
UserName=test #FTP用户名
Passwd=test #FTP密码
命令行是一个强大的工具,而我们大多数却都不会用,可以说没有命令行的世界等于你失去了一多半的乐趣和技能。
本文虫虫和大家一起来聊聊命令行,并教大家一起来学习命令,不管你是运维、开发、测试、DBA,甚至是项目经理、PM都能通过命令行获得很大的裨益。当然我们主要是以开发了主要受众来举例子说明。
日常编码时,你是选择集成开发环境IDE呢,还是文本编辑器(Vim、Emacs、sublime)+插件+命令行呢?
现代IDE(VS、Eclipse、IDEA等)可以一个界面提供给我们所有必需的开发工具:代码版本,语法高亮,自动格式化,自动补全,版本控制,编译,调试、可视化断点、还有运行时环境!一键编译、一键运行,那么,为什么选择简单的文本编辑器呢?
对这个问题,有很多问题、当然可能有一个原因是IDE太慢了!就个人而言,主要是是对于简单的项目和脚本,使用轻量化的文本编辑以及一些插件,一方面可以节省我编译的时间,而且我更喜欢欢命令行的各个工具栈套件GCC+GDB等强大的编译调试套件,更加适合我的胃口。
我更喜欢学习掌握每个工具,比如GDB强大的各种特性和命令,可以让你更加编辑的操作,用键盘而不是点鼠标,还有就是让你可以更深入到程序和开发的精髓之处。。
听起来有点泛泛而谈,但在IDE中,我们时常会受到约束并受限于固定的功能项,而在命令行中,有许多工具,脚本,框架可以在借鉴,支持多环境,许多语言以及Linx下强大的Shell流水栈、Perl onelines等可以把许多最高效最优秀的工具连接起来,最主要你随时可以修改完善他们,甚至自己造个更趁手的工具。
当然,如果你是在Windows使用命令行,虽然现在Powershell已经增强改善了很多很多,以及有WSL的Linux子系统,但是由于其终端模拟器的限制,你可能还是可能会有不爽之处,所以建议你来使用Linux,Mac也是个很棒的选择。
为啥,我只举两个个例子Docker,时下最火的容器技术,以及Git服务器Gitlab都是只支持Linux的,你还想多学点技术,Linux是不好躲的。
Fish shell(或“fish”)是一个面向用户交互的shell,它是日常和交互式使用的良好候选者。我们很多人可能都用的是Bash,但是说实话Bash更适合做脚本而Fish则更加人性化,更适合做交互操作。
Fish shell包括许多命令和工具的原生语法高亮,也原生支持自动完成。
Zsh是这种用例的另一种可靠替代方案。
以下是使用git自动完成的示例:
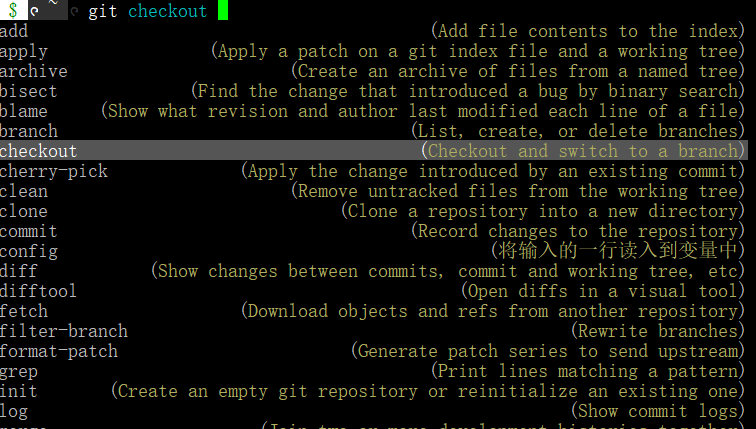
通过敲打git,空格,在输入<tab>,fish会列出git命令列表(checkout,commit,log,…)。通过反复敲<tab>建,可以浏览命令直到达到所需的命令,然后我们只需输入回车(例如git checkout),这时fish就显示它的强大的魔力,他可以自动列出你仓库的分支和Tag列表。当然对其他工具,fish也是有很多类似的魔力的,你需要做的就是安装并且使用探索它。

这儿我推荐两个框架可以增强的fish的功能:oh-my-fish(github/oh-my-fish)和fisherman(github/fisherman)。
oh-my-fish

fisherman

它们都可以用来给提示符和各种插件安装主题样式。
你可能会说,定制提示符能有啥蛋用呢,但当你只面对一个主窗口的时候,那么定制它就很有必要了。比如
当你用git的时候,用他可以告诉我们:
当前所处的分支;
你要push/pull的远程仓库地址是啥;
你的索引干净,有没有你有未提交或未跟踪的文件;
等等。
一般情况下时候:
你当前目录(pwd);
你上一条执行的命令是啥(!);
上一条命令的状态($?);
上一条命令的响应时间;
等等。
系统可以有几十个提示可供自由选择,因此大家都可以按照自己喜好和需求进行选择。我一般用两个:bobthefish和neolambda主题,你可以在oh-my-fish框架下安装:omf install bobthefish。他可以提供:
第一个主题bobthefish,高度可视化,基于powerline,Vim的状态行,包括许多模式和符号,使其更加用户友好:

后一个主题neolambda更时尚,功能更少,但有趣(omf install neolambda):

除了命令提示符,许多插件允许增强用户界面,值得推荐的有:
colorman,为man添加语法高亮显示(omf install colorman)
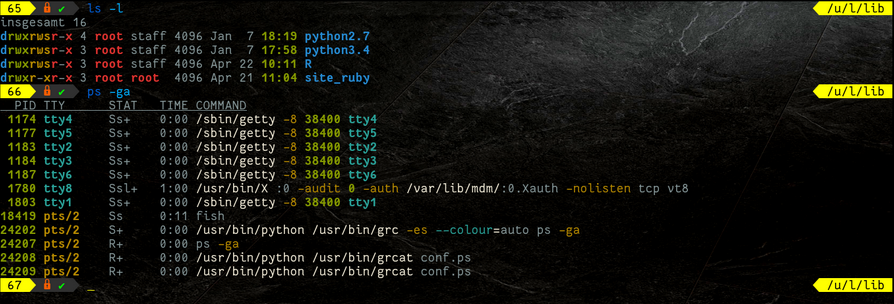
grc为Linux命令添加语法高亮,比如cat,cvs,df,diff,dig,gcc,ping,ps...(omf install grc)
g2是一个简化git命令的打包。
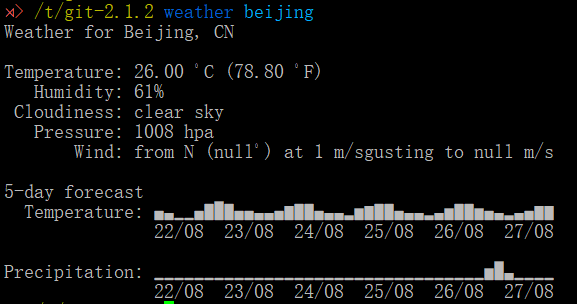
weather在 Fish shell 中使用以下命令查看天气。(注意该插件依赖jq来处理json数据需要先安装yum install jq 安装,后面日志部分会介绍)。
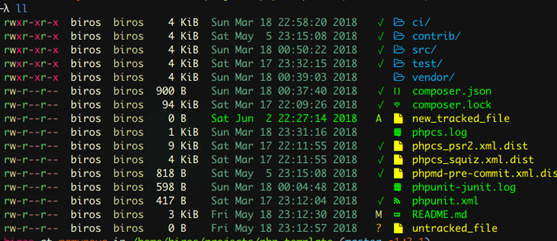
colorls(gem install colorls),这个美化的ls工具是必备的。他非常好看,使用用颜色变化来突出当前目录文件的修改工具期。它使文件大小做对人友好话适配(-h);最重要的是,它显示可以当前文件/文件夹的git状态!
如果你是,运维或或者开发人员工程师,那么日志可视化是你日常一项重复性任务,你必须选择好的工具才能提高工作效率。
现代IDE都不适合查看日志,因为它们已经被源文件过载,而且它日志文件通常尺寸都不小,会严重影响你编辑器的性能。一旦文件大小超过10Mb,大多数IDE和编辑器都会“卡壳”。
解决方案:使用head和tail工具来得到最先或者最新的日志,同时从可用于shell中的grep、awk、sort、uniq等形成流水处理栈,你可以启用语法突出显示并执行搜索。
根据日志类型,我们在还这推荐两个工具
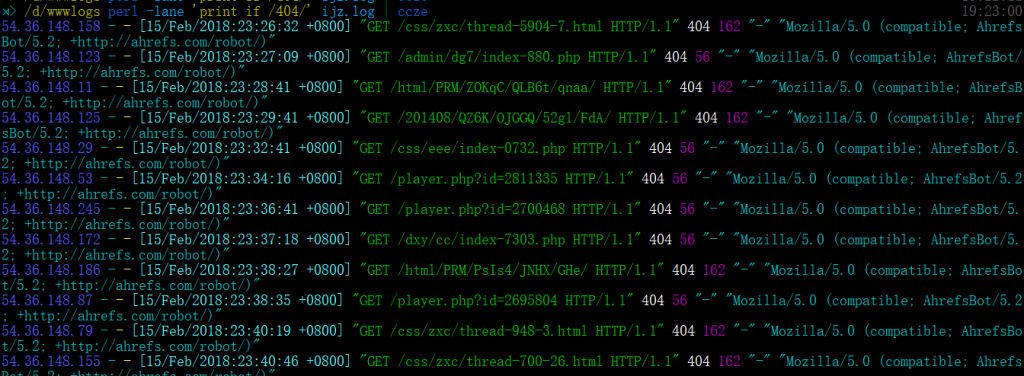
ccze用于传统日志(Apache,syslog,php,…)
jq用于JSON日志
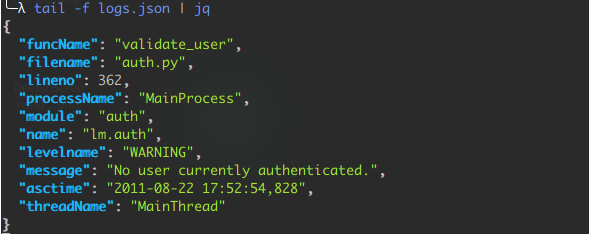
jq的好处是,除了JSON语法突出显示之外,它还会自动格式化你的日志,以方便阅读。因此,如果你的ELK或任何其他数据分析栈如果有单行压缩的JSON日志,你可以用jq解压缩日志并使其做人性化阅读适配。jq是一个功能更强大的工具,它还自带有描述语言的JSON解析器,与XML的xpath类似,但JSON的最简单。
因此,通过命令行的tail -f access 实时获取最新每个日志行,并根据类型将stdout传送到jq或ccze,你就可以快速得到所需信息,并以优雅人性化的格式呈现在你的眼前。
命令行的世界丰富多彩,群芳流彩,虫虫在此列一些我收集到很好的工具。
ccat:cat的语法高亮显示
tig:允许增强许多已知git命令的输出(例如git log|tig)
howdoi:常量格式化工具,可生成多种语言的格式,比如你需要python的格式,那么只需输入howdoi format date python。
你要显示tar命令你只需 howdoi create tar archive
会显示 > tar -cf backup.tar --exclude "www/subf3" www
htop:炫酷当前进程列表展示。
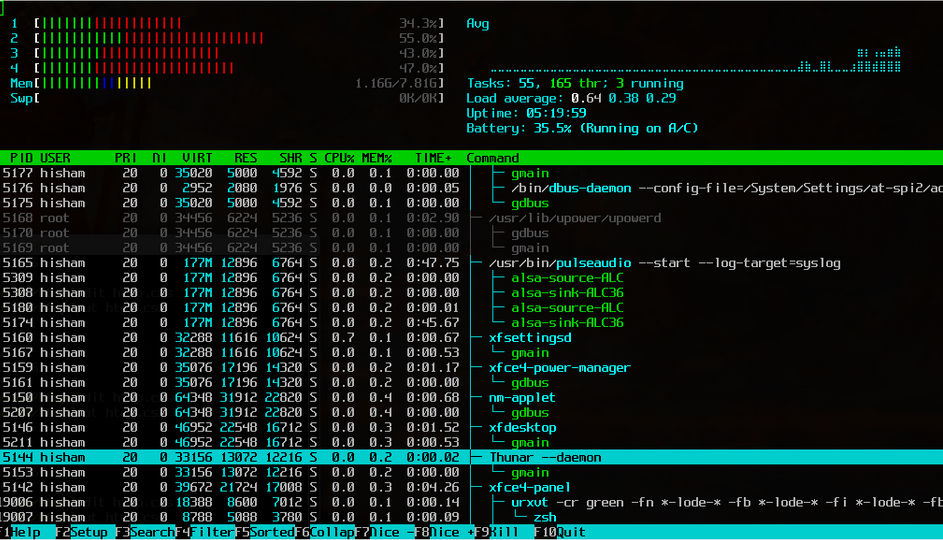
glances(pip install glances):计算机的监控控制台(进程,内存,网络,磁盘I/O,绑定器……)
clog(cargo install clog):从你的git repo的元数据生成CHANGELOG。
googler:命令行下搜索,SSH肉身搜索。
you-get和youtube-dl:命令行下载视频:

dockly(npm install -g dockly):监控你的指定的容器及Docker镜像:
newman(npm install -g newman):你想将Postman集成到CI/CD Pipeline中吗?newman就是专门干这个的!
ttyrec/ttygif:通过shell会话创建GIF动画。
对于上面引用的每个命令/工具,我都在其名称后的括号里附上了安装命令(主要有yum pip npm等)。如果不能通过包管理器安装,请你下载源码安装。如果你有更好的工具也请留言告诉我和大家分享。炎炎夏日,让我们一起来命令行的世界沐浴来把!
]]>perl -ne 'print if 5..10' xxoo #感谢flw提醒,忘记这个了
perl -ne 'print if $.>=5 and $.<=10' xxoo
perl -ne 'print if int($.) ~~ (5..10)'
perl -ne 'print if grep { $_ == $. } 5..10'xxoo
sed -ne '5,10 p' xxoo
awk 'NR==5,NR==10' xxoo
head -10 xxoo |tail -6
tail -n +5 xxoo | head -n 6
grep . -n xxoo |grep -E "^(5|6|7|8|9|10):"|perl -lpe 's/\d+://'
本文总结了,生物信息处理过程中常见一些工具和单行命令等。
awk和sed基础
提取文件中的2, 4, and 5 列:
awk ‘{print $2,$4,$5}’ file.txt
输出第五列等于abc123的行:
awk ‘$5 == “abc123″‘ file.txt
输出第五列不是abc123的行:
awk ‘$5 != “abc123″‘ file.txt
输出第七列以字母a-f开头的行:
awk ‘$7 ~ /^[a-f]/’ file.txt
输出第七列不是以字母a-f开头的行:
awk ‘$7 !~ /^[a-f]/’ file.txt
计算第二列不重复的值保存在哈希arr中 (一个值只保存一次):
awk ‘!arr[$2]++’ file.txt
输出第三列的值比第五列大的行:
计算文件中第一列的累加值,输出最后的结果:
awk ‘{sum+=$1} END {print sum}’ file.txt
计算第二列的平均值:
awk ‘{x+=$2}END{print x/NR}’ file.txt
用bar替换文件中所有的foo:
sed ‘s/foo/bar/g’ file.txt
消除行开头空和格制表符:
sed ‘s/^[ \t]*//’ file.txt
消除行结尾的空格和制表符:
sed ‘s/[ \t]*$//’ file.txt
消除行中开头和结尾的空格和制表符:
sed ‘s/^[ \t]//;s/[ \t]$//’ file.txt
删除空行:
删除包含‘EndOfUsefulData’的行及其后所有的行:
sed -n ‘/EndOfUsefulData/,$!p’ file.txt
生信sed,awk单行应用
Returns all lines on Chr 1 between 1MB and 2MB in file.txt. (assumes) chromosome in column 1 and position in column 3 (this same concept can be used to return only variants that above specific allele frequencies):
输出Chr为1在1M和2M之间的所有行。(假设)染色体在第一列,位点在第三列(基于同样的假设可以用来返回类似特定等位基因频率的变异)
cat file.txt | awk ‘$1==”1″‘ | awk ‘$3>=1000000’ | awk ‘$3<=2000000’
Basic sequence statistics. Print total number of reads, total number unique reads, percentage of unique reads, most abundant sequence, its frequency, and percentage of total in file.fq: 基本序列统计。输出总的reads数,不重复的reads总数,不重复reads百分比,最大冗余的序列及其频度以及总占比百分数。
cat myfile.fq | awk ‘((NR-2)%4==0){read=$1;total++;count[read]++}END{for(read in count){if(!max||count[read]>max) {max=count[read];maxRead=read};if(count[read]==1){unique++}};print total,unique,unique100/total,maxRead,count[maxRead],count[maxRead]100/total}’
转换.bam为.fastq:
samtools view file.bam | awk ‘BEGIN {FS=”\t”} {print “@” $1 “\n” $10 “\n+\n” $11}’ > file.fq
Keep only top bit scores in blast hits (best bit score only): 只取blast采样中的顶级位点的分数(最高的位点分)
awk ‘{ if(!x[$1]++) {print $0; bitscore=($14-1)} else { if($14>bitscore) print $0} }’ blastout.txt
Keep only top bit scores in blast hits (5 less than the top): 只取blast采样中的顶级位点的分数(比顶级少于5的)
awk ‘{ if(!x[$1]++) {print $0; bitscore=($14-6)} else { if($14>bitscore) print $0} }’ blastout.txt
分割多序列FASTA文件为单序列FASTA文件
awk ‘/^>/{s=++d”.fa”} {print > s}’ multi.fa
输出fasta文件中的每条序列的序列名称和长度
cat file.fa | awk ‘$0 ~ “>” {print c; c=0;printf substr($0,2,100) “\t”; } $0 !~ “>” {c+=length($0);} END { print c; }’
转化FASTQ文件为FASTA:
sed -n ‘1~4s/^@/>/p;2~4p’ file.fq > file.fa
从第二行开始每四行取值(从FASTQ文件提取序列)。
输出中剔除第一行:
输出20-80行:
awk ‘NR>=20&&NR<=80’ input.txt
计算二,三行列的和并追加到每行后输出
awk ‘{print $0,$2+$3}’ input.txt
计算fastq文件平均reads的长度
awk ‘NR%4==2{sum+=length($0)}END{print sum/(NR/4)}’ input.fastq
转化VSF文件为BED文件
sed -e ‘s/chr//’ file.vcf | awk ‘{OFS=”\t”; if (!/^#/){print 1,2-1,2,4″/”$5,”+”}}’
sort, uniq, cut等杂项
输出带行号的内容:
去重复行计数
cat file.txt | sort -u | wc -l
找到两文件都有的行(假设两个文件都是无重复行,重定向执行‘wd -l’计算同样行的行数)
sort file1 file2 | uniq -d
sort -u file1 > a
sort -u file2 > b
sort a b | uniq -d
comm -12 file1 file2
对文件按照第九列数字顺序排序(g按照常规数值,k列)
找到第二列出现最多的字符串
cut -f2 file.txt | sort | uniq -c | sort -k1nr | head
从文件中随机取10行
shuf file.txt | head -n 10
输出所有三个所可能的DNA序列
echo {A,C,T,G}{A,C,T,G}{A,C,T,G}
Untangle an interleaved paired-end FASTQ file. If a FASTQ file has paired-end reads intermingled, and you want to separate them into separate /1 and /2 files, and assuming the /1 reads precede the /2 reads:
解开一列交错paired-end fastq文件。如果fastq文件有乱序paired-end reads,你想将其分离成单独的/1,/2的文件保存,这里假设/1 reads 在/2 前面:
cat interleaved.fq |paste – – – – – – – – | tee >(cut -f 1-4 | tr “\t” “\n” > deinterleaved_1.fq) | cut -f 5-8 | tr “\t” “\n” > deinterleaved_2.fq
Take a fasta file with a bunch of short scaffolds, e.g., labeled >Scaffold12345, remove them, and write a new fasta without them:
将一个fasta文件转成一系列短的scaffolds。比如,标签 “>Scaffold12345″,然后移出他们,保存一个去掉他们的新文件:
samtools faidx genome.fa && grep -v Scaffold genome.fa.fai | cut -f1 | xargs -n1 samtools faidx genome.fa > genome.noscaffolds.fa
Display hidden control characters:
显示一个隐藏的控制字符:
python -c “f = open(‘file.txt’, ‘r’); f.seek(0); file = f.readlines(); print file”
find, xargs,和GNU parallel
通过 https://www.gnu.org/software/parallel/. 载 GNU parallel
搜索文件夹及其子目录中名称为 .bam 文件(目录也算):
删除上面搜到的文件列表(不可逆的危险操作,谨慎使用!删除之前请自习确认)
find . -name “*.bam” | xargs rm
将所有.txt 文件修改为.bak(例如在对*.txt做操作之前用于文件备份)
find . -name “*.txt” | sed “s/.txt$//” | xargs -i echo mv {}.txt {}.bak | sh
Chastity filter raw Illumina data (grep reads containing :N:, append (-A) the three lines after the match containing the sequence and quality info, and write a new filtered fastq file):
对Illumina数据做Chastity过滤(grep 查询 包含:N:,用(-A)选项第三列信息附加在匹配的包含一个序列质量信息后,并保存为一个新的fasta文件)
find fq | parallel “cat {} | grep -A 3 ‘^@.[^:]:N:[^:]:’ | grep -v ‘^–$’ > {}.filt.fq”
通过parallel并行运行12个FASTQC任务
find *.fq | parallel -j 12 “fastqc {} –outdir .”
通过parallel给bam做索引,通过–dry-run打印测试这些命令,实际上并未做执行。
find *.bam | parallel –dry-run ‘samtools index {}’
seqtk
Seqtk项目托管地址https://github.com/lh3/seqtk。Seqtk是一个快捷轻量的处理FASTA和FASTQ格式基因序列的工具。他可以是先FASTA和FASTQ无缝处理和转化,同时支持gzip格式的压缩文件。
把FASTQ转化为FASTA:
seqtk seq -a in.fq.gz > out.fa
转化ILLUMINA 1.3+ 格式FASTQ为FASTA,并且以小于20的mask bases获得小写字母(第一命令行)或者到N(第二)。 seqtk seq -aQ64 -q20 in.fq > out.fa seqtk seq -aQ64 -q20 -n N in.fq > out.fa
折叠长FASTA/Q行,并且去除其注释:
seqtk seq -Cl60 in.fa > out.fa
转化多行FASTQ到四行FASTQ:
seqtk seq -l0 in.fq > out.fq
反转FASTA/Q序列:
seqtk seq -r in.fq > out.fq
用序列文件中的名称(比如name.1st)提取序列,一个虚列名一行:
seqtk subseq in.fq name.lst > out.fq
利用序列文件中的”reg.bed“r信息提取地理信息的序列:
seqtk subseq in.fa reg.bed > out.fa
编码‘reg.bed’信息为小写
seqtk seq -M reg.bed in.fa > out.fa
从两个大的paired FASTQ文件提取10000个read pairs(记得用同样的随机种子保持 paire)
seqtk sample -s100 read1.fq 10000 > sub1.fq
seqtk sample -s100 read2.fq 10000 > sub2.fq
利用Phred公式从两头修剪低质量bases:
seqtk trimfq in.fq > out.fq
从左端修剪5bp,从右端修剪10bp的。
seqtk trimfq -b 5 -e 10 in.fa > out.fa
seqtk seq -l0 -1 interleaved.fq > deinterleaved_1.fq
seqtk seq -l0 -2 interleaved.fq > deinterleaved_2.fq
GFF3 Annotations
输出GFF3文件中标注的所有的序列
cut -s -f 1,9 yourannots.gff3 | grep $’\t’ | cut -f 1 | sort | uniq
检测GFF3文件中标注的所有性状类型。
grep -v ‘^#’ yourannots.gff3 | cut -s -f 3 | sort | uniq
检测GFF3文件中标注的基因数量。
grep -c $’\tgene\t’ yourannots.gff3
从GFF3文件中提取所有的基因ID
grep $’\tgene\t’ yourannots.gff3 | perl -ne ‘/ID=([^;]+)/ and printf(“%s\n”, $1)’
输出GFF3文件每个基因的长度
grep $’\tgene\t’ yourannots.gff3 | cut -s -f 4,5 | perl -ne ‘@v = split(/\t/); printf(“%d\n”, $v[1] – $v[0] + 1)’
FASTA头列转化为GFF格式(假设头的长度,附加在”_length“ ,和Velvet assembled transcripts))
grep ‘>’ file.fasta | awk -F “” ‘BEGIN{i=1; print “##gff-version 3″}{ print $0″\t BLAT\tEXON\t1\t”$10″\t95\t+\t.\tgene_id=”$0”;transcript_id=Transcript“i;i++ }’ > file.gff
有用的别名(.bashrc)
提示符修改为user@hostname:/full/path/cwd/:$ 形式
export PS1=”\u@\h:\w\$ ”
避免反复敲诸如cd ../../..的命令(也可以用[autojump](https://github.com/joelthelion/autojump),让你在飞速的转换目录
alias ..=’cd ..’
alias …=’cd ../../’
alias ….=’cd ../../../’
alias …..=’cd ../../../../’
alias ……=’cd ../../../../../’
向前和向后浏览
alias u=’clear; cd ../; pwd; ls -lhGgo’
alias d=’clear; cd -; ls -lhGgo’
覆盖文件时候,先确认
alias mv=”mv -i”
alias cp=”cp -i”
alias rm=”rm -i”
我最喜欢的”ls“别名
alias ls=”ls -1p –color=auto”
alias l=”ls -lhGgo”
alias ll=”ls -lh”
alias la=”ls -lhGgoA”
alias lt=”ls -lhGgotr”
alias lS=”ls -lhGgoSr”
alias l.=”ls -lhGgod .*”
alias lhead=”ls -lhGgo | head”
alias ltail=”ls -lhGgo | tail”
alias lmore=’ls -lhGgo | more’
对cut空格和逗号,分割文件
alias cuts=”cut -d \” \””
alias cutc=”cut -d \”,\””
解压缩tar包
alias tarup=”tar -zcf”
alias tardown=”tar -zxf”
或者可以用更普遍的‘extract’函数
源于ABSG(Advanced Bash Scripting Guide)中 Mendel Cooper的建议
extract () {
if [ -f $1 ] ; then
case $1 in
*.tar.bz2) tar xvjf $1 ;;
*.tar.gz) tar xvzf $1 ;;
*.tar.xz) tar Jxvf $1 ;;
*.bz2) bunzip2 $1 ;;
*.rar) unrar x $1 ;;
*.gz) gunzip $1 ;;
*.tar) tar xvf $1 ;;
*.tbz2) tar xvjf $1 ;;
*.tgz) tar xvzf $1 ;;
*.zip) unzip $1 ;;
*.Z) uncompress $1 ;;
*.7z) 7z x $1 ;;
*) echo “don’t know how to extract ‘$1’…” ;;
esac
else
echo “‘$1’ is not a valid file!”
fi
}
使用别名”mcd”创建一个目录,并且cd到该目录
function mcd { mkdir -p “$1” && cd “$1”;}
跳转到上级目录,并且列出其内容
一个好看的grep
alias grep=”grep –color=auto”
刷新你的.bashrc
alias refresh=”source ~/.bashrc”
编辑你的.bashrc
常用错误别称
alias mf=”mv -i”
alias mroe=”more”
alias c=’clear’
使用 pandoc转化markdown文档为PDF格式:
alias mdpdf=”pandoc -s -V geometry:margin=1in -V documentclass:article -V fontsize=12pt”
对当前目录搜索关键词(ft “mytext” *.txt):
function ft { find . -name “$2” -exec grep -il “$1” {} \;; }
Etc
重复运行上一条命令:
sudo !!
‘ALT+.’ or ‘<ESC> .’
敲出了部分命令,删除这些输入,查你忘记的明亮,拉回命令,继续输入(删除光标之前的输入,恢复上个C-U删除字符)
<CTRL+u> […] <CTRL+y>
跳到一个目录,执行命令,然后返回当前目录(()的用法)
记时秒表 (输入Enter or ctrl-d 停止):
把上次执行的命令生成一个脚本
重用上次命令的所有参数
列出或者删除一个目录中所有不匹配的特定后缀的文件(例如,列出所有不是压缩的文件,删除所有不以.foo和.bar后缀的文件)
ls !(*.gz)
rm !(.foo|.bar)
利用上次的命令,但是不需要他的的参数(重新输入参数):
!:- <new_last_argument>
激活一个快捷的编辑器,输入,编辑长的,复杂,巧妙的命令:
输出一个特定的行(比如 42行)
终结一个冻结的ssh session(会车换行,敲~键,在敲下.键)
利用grep去除文件的空行,结果保存到新文件
grep . filename > newfilename
查找大文件(例如,大于500M的)
find . -type f -size +500M
利用截取列(例如,一个tab分割文件的第五个域)
cut -f5 --complement
查找包含特定字符的文件(-l 只输出文件名, -i 忽略大小写 -r 遍历子目录)
grep -lir "some text" *
#!/bin/bash
# 0 00 * * * /nginx/logs/ngx_logcut.sh >/dev/null 2>&
pidfile=/var/run/nginx.pid
logpath='/nginx/logs/'
keepdays=30
logfiles=(access.log error.log)
cd $logpath
for logfile in ${logfiles[@]}; do
if [ ! -e $logfile ];
then
continue
fi
find . -type f -name $logfile"20*" -mtime +$keepdays -exec rm {} ;
mv $logfile $logfile$(date -d "yesterday" +"%Y%m%d")
done
kill -USR1 `cat $pidfile`]]>
mail -s test [email protected]
这条命令的结果是发一封标题为test的空信给后面的邮箱,如果你有mta并且后面的邮箱不会挡这种可能莫名奇妙的信的时候,就能收到这封信了。如果你不想被这种乱七八糟的事情干扰,后面的邮箱请使用本地帐户。
2. 第二个例子:
三种常用格式发信
mail -s test [email protected]
#第一种方法,你可以把当前shell当成编辑器来用,编辑完内容后Ctrl-D结束
echo “mail content”|mail -s test [email protected]
#第二种方法,我用的最多,可能是喜欢管道的缘故吧
mail -s test [email protected] < file
#第三种方法,以file的内容为邮件内容发信
其实你很容易发现mail从标准输入读取文件内容并发信,我也只想让你知道这一点,到此,第二个例子结束。
3. 第三个例子,带附件的邮件
如果你的系统里没有uuencode命令的话,请先安装sharutils(yum install sharutils)
uuencode 需要两个参数,第一个是你要发送的文件(们),当然这个也可以用管道来做,第二个是显示的文件名
uuencode /tmp/a.gif a.gif|mail -s pictest [email protected]
tar czf – /tmp/ | uuencode tmp.tar.gz |mail -s pictest [email protected]
———————————-
系统收到邮件都会保存在“/var/spool/mail/[linux用户名]”文件中。
在linux中输入mail,就进行了收件箱,并显示二十封邮件列表。
此时命令提示符为”&”
unread 标记为未读邮件
h|headers 显示当前的邮件列表
l|list 显示当前支持的命令列表
?|help 显示多个查看邮件列表的命令参数用法
d 删除当前邮件,指针并下移。 d 1-100 删除第1到100封邮件
f|from 只显示当前邮件的简易信息。 f num 显示某一个邮件的简易信息
f|from num 指针移动到某一封邮件
z 显示刚进行收件箱时的后面二十封邮件列表
more|p|page 阅读当前指针所在的邮件内容 阅读时,按空格键就是翻页,按回车键就是下移一行
t|type|more|p|page num 阅读某一封邮件
n|next|{什么都不填} 阅读当前指针所在的下一封邮件内容,阅读时,按空格键就是翻页,按回车键就是下移一行
v|visual 当前邮件进入纯文本编辑模式
n|next|{什么都不填} num 阅读某一封邮件
top 显示当前指针所在的邮件的邮件头
file|folder 显示系统邮件所在的文件,以及邮件总数等信息
x 退出mail命令平台,并不保存之前的操作,比如删除邮件
q 退出mail命令平台,保存之前的操作,比如删除已用d删除的邮件,已阅读邮件会转存到当前用户家目录下的mbox文件中。如果在mbox中删除文件才会彻底删除。
在linux文本命令平台输入 mail -f mbox,就可以看到当前目录下的mbox中的邮件了。
cd 改变当前所在文件夹的位置
写信时,连按两次Ctrl+C键则中断工作,不送此信件。
读信时,按一次Ctrl+C,退出阅读状态。
扫描登录失败的日志:
less secure*|grep “Failed password for root from” >/tmp/gj.list
对扫描日志进行分析,非法尝试失败超过50的ip列出来,保存为gongji.ip
cat /tmp/gj.list|perl -anle ‘print $F[10]’|sort |uniq -c|sort -n |perl -anle ‘print $F[1] if $F[0]>50 ‘>/tmp/gongji.ip
二、安装ipset进行ip管理(略)
三、在ipset中创建一个ip组用于存放非法ip
ipset -N banip iphash
四、写个脚本本将ip加入banip分组
vim ipsetadd.sh
_input=/tmp/gongji.ip
IPS=/usr/sbin/ipset
egrep -v "^#|^$" $_input | while IFS= read -r ip
do
$IPS -A banip $ip
done
执行sh ipsetadd.sh
五、iptables 禁止这些ip
iptables -I INPUT -m set –match-set banip src -p tcp -j DROP
ok,收工
]]>
function Iint() #处理涵数
{
backup_path=/home/mysqlbackup #压缩文件存放的目录
file=$path-mysql-$(date +%Y-%m-%d).tar.gz #文件名
backupCWD=/usr/local/mysql/data/$path #需备份的path
tar -Pczf $backup_path/$file $backupCWD #执行备份操作
cd $backup_path
ftp -i -n <<!
open $host
user $UserName $Passwd
cd MYSQL-BACK/$path
put $file
bye
!
}
/etc/init.d/mysqld stop >/dev/null 2>&1 #停止Mysql服务
path=database1 #需备份的数据名
Iint #调用处理涵数
path=datebase2
Iint
/etc/init.d/mysqld start >/dev/null 2>&1 #启动Mysql服务
rm -rf $backup_path/*.tar.gz #删除压缩文件
echo “ftp back ok!”
1 tput
在使用tput前,需要在脚本或命令行中使用tput命令初始化终端.
$ tput init
tupt产生三种不同的输出:字符型,数字型和布尔型(真,假)
1.1 字符串输出
常用字符串有:
名字 含义
bel 警铃
blink 闪烁模式
bold 粗体
civis 隐藏光标
clear 清屏
等等
1.2 数字输出
常用数字输出:
名字 含义
cols 列数目
it tab设置宽度
lines 屏幕行数
1.3 布尔输出
在tput种只有两种布尔操作符
名字 含义
chts 光标不可见
hs 具有状态行
2 tput 用法
2.1 设置tput命令
可以取得所有tput名字输出,将其保存为更有意义的变量名.格式如下:
variable_name=’tupt name’
2.2 使用布尔输出
可以在if语句种使用布尔型tput输出.
STATUS_LINE=’tput hs’
if $STATUS_LINE; then
echo103f “your terminal has a status line”
else
echo “your terminal has NO status line”
fi
2.3 在脚本中使用tput
以下脚本设置tput bel和cl为更有意义的变量名.
$ vi tput1
#!/bin/bash
BELL=tput bel
CLEAR=tput cl
echo $BELL
echo $CLEAR
2.4 产生转义序列
所有控制字符均以一个转义序列开始,通常转义键后紧跟字符[.然后实际序列打开或关闭某终端属性.
2.5 光标位置
可以用tput将光标放在屏幕任意位置.格式为:
cup r c
r 为从上至下屏幕行数,c为穿过屏幕列数
最好将之编成函数,这样就可以把行和列的值传递给它.
2.6 在屏幕中心位置显示文本
在屏幕中心位置显示文本不是很麻烦.首先从tput中得到列数,然后算出所提供的字符串长度,从tput列数中减去该值,结果再除以2,所得结果可用于显示的字符串行数.
2.7 在脚本中使用功能键
使用cat命令可以查看发送的任意特殊键控制序列(F1,上箭头等),键入cat -v,然后按任意控制键,回车,在下一行就可以知道终端发送了什么功能键.结束后按<ctrl-c>退出.
2.8 使用颜色
对域使用颜色可以使数据输入屏幕看起来更加专业.显示前景或背景颜色格式为:
<ESCAPE> [background_number;foreground_number m
2.9 产生颜色
产生颜色需要在echo语句中嵌入控制字符.这种方法适用于带有彩色终端的任何系统.与在控制字符里一样,可以在echo语句里使用转义序列产生颜色.
要产生一个黑色背景加绿色前景色:
echo -e “�33[40;32m”
2.10 创建精致菜单
3 小结
使用tput命令可以增强应用外观及脚本的控制.颜色设置可以增加应用的专业性.注意使用颜色不要太过火,这也许对你来说很好,但其他用户使用这段脚本时看到这种屏幕设置也许会感到厌烦.可以使用和读取控制字符来增加脚本的灵活性,特别是对用户击键输入操作更是如此.
]]>